概述
蒙特卡洛方法(Monte Carlo),也称为统计模拟方法或者随机抽样方法,是一类利用 随机数(概率统计方法) 来求解数学问题、数值积分或复杂模型近似解的算法。
其基本思想是:
$$ \text{用大量随机样本的统计特性来逼近问题的真实解。} $$换句话说:
- 随机试验 → 统计规律 → 近似解
名字来源于摩纳哥的 Monte Carlo 赌场 🎲,因为方法核心是 “随机抽样”。
假设我们要求一个积分:
$$ I = \int_a^b f(x)\, dx $$普通数值积分(梯形法、辛普森法)在高维时非常复杂。 但蒙特卡洛方法的想法是:
在 $[a,b]$ 上随机生成 $N$ 个样本 $x_1, x_2, \dots, x_N$。
计算函数值的平均:
$$ \hat{I} = (b-a)\cdot \frac{1}{N}\sum_{i=1}^N f(x_i) $$根据大数定律,当 $N \to \infty$,$\hat{I} \to I$。
蒙特卡洛方法的主要特点是:
- 维度不敏感:在高维积分、复杂概率分布下依然适用(相比传统数值方法不爆炸)。
- 简单易实现:只要能生成随机数,就能用。
- 误差随样本数衰减:
与维度无关,但收敛速度较慢。
- 普适性强:可用于积分、优化、概率模拟、物理建模、统计推断等。
蒙特卡洛方法的常见应用有:
- 积分估计(尤其是高维积分,如贝叶斯后验概率)
- π 的估计(经典例子:随机撒点看落在圆内比例)
- 随机模拟(金融期权定价、排队论、风险分析)
- 统计推断(MCMC,重要性采样,Bootstrap)
- 物理建模(粒子输运、热传导、蒙特卡洛光线追踪)
总而言之,
蒙特卡洛方法 = “随机试验 + 统计规律” 它不是某一个具体算法,而是一整类算法。核心在于:
- 用随机数来模拟问题
- 用统计平均来逼近答案
- 利用大数定律和中心极限定理保证正确性
蒙特卡罗方法的基本形式
| 方法 | 描述 |
|---|---|
| 均匀采样 | 最基本,理解“扔飞镖” |
| 接受-拒绝采样 | 复杂分布采样的万能工具 |
| 重要性采样 | 积分估计的核心技巧 |
| 方差缩减 | 提高效率的必修课 |
均匀采样:区间/区域上的均匀采样
思想:把样本空间限制在某个有限测度的集合 $S$(即长度/面积/体积可数,且 $0<\mu(S)<\infty$)。 连续情形的“均匀分布” 就是:对任意事件 $A$,
$$ P(X\in A)=\frac{\mu(A\cap S)}{\mu(S)}. $$在概率论里,我们要把“几何大小”和“概率”对应起来。这个“几何大小”一般记作 测度(measure),符号常用 $\mu$ 来表示。 在一维区间里,$\mu$ 就是长度;在二维平面里,$\mu$ 就是面积;在三维空间里,$\mu$ 就是体积。 当我们说“均匀分布”,意思是 $P(\text{落在 } A) \propto \mu(A)$。即:概率只和区域的大小成正比,而不依赖它的位置或形状。 但为了保证整个空间的概率总和 = 1,我们要做归一化:$P(X \in A) = \frac{\mu(A \cap S)}{\mu(S)}$。 例如,在 $[2,5]$ 上:总长度 $\mu(S)=3$。如果 $A=[2,3]$,长度 $\mu(A)=1$,所以概率是 $1/3$。
也就是说,概率正比于几何测度。等价地,它的密度是
$$ f_X(x)=\frac{1}{\mu(S)}\ \text{(在 }x\in S\text{ 时)},\quad 0\ \text{(否则)}. $$离散情形:若 $S=\{1,\dots,n\}$,则每个点的质量都是 $1/n$。
直觉:像往 $S$ 里“等可能地扔飞镖”,命中哪块区域的机会只取决于这块区域的“大小”。
又见https://www.xuqiongjie.com/zh-cn/post/mcmc-statics/random-variables/#反函数法inverse-transform-sampling
为什么能从 $U(0,1)$ 得到别处的均匀
关键是测度保持的变换。
区间上的仿射变换 若 $U\sim \mathrm{Uniform}(0,1)$,设
$$ X=a+(b-a)\,U\qquad (aCDF 法:对任意 $x\in[a,b]$,
$$ P(X\le x)=P\!\Big(U\le \frac{x-a}{b-a}\Big)=\frac{x-a}{b-a}. $$这正是 $\mathrm{Uniform}(a,b)$ 的 CDF。
换元/密度法:$u=(x-a)/(b-a)\Rightarrow f_X(x)=f_U(u)\,\bigl|\frac{du}{dx}\bigr|=1\cdot \frac{1}{b-a}$。
更高维的线性/仿射变换:把 $(U_1,\dots,U_d)\sim \mathrm{Uniform}([0,1]^d)$ 线性映到一个长方体,就得到该长方体上的均匀分布(Jacobian 是常数)。
一般区域 $S$ 上:如果没有现成的测度保持映射,常用接受-拒绝,见下一个方法。
示例:在区间 $[2,5]$ 上均匀采样(并证明为何可行)
构造:取 $U\sim \mathrm{Uniform}(0,1)$,令
$$ X=2+3U. $$为什么可行(严格):
CDF 证明:对任意 $x\in[2,5]$,
$$ P(X\le x)=P\!\Big(U\le \frac{x-2}{3}\Big)=\frac{x-2}{3}. $$这正是 $\mathrm{Uniform}(2,5)$ 的分布函数;区间外概率为 0 或 1。
密度证明:由换元 $u=(x-2)/3$ 得
$$ f_X(x)=f_U(u)\left|\frac{du}{dx}\right|=1\cdot \frac{1}{3}=\frac{1}{3},\quad x\in[2,5], $$其他地方为 0。和“长度比例”一致:任意子区间 $A\subset[2,5]$ 有
$$ P(X\in A)=\frac{|A|}{|[2,5]|}=\frac{|A|}{3}. $$
这就是“从 $U(0,1)$ 通过仿射变换得到任意区间上的均匀”的标准做法;背后就是测度按常数缩放的换元公式。
区域上的均匀采样
对一个有“体积”(面积/体积)可度量的集合 $S$,均匀分布的密度就是在 $S$ 内为常数、外面为 0。要从 $U(0,1)$ 构造出 $S$ 上的均匀样本,可以利用几何构造(用正确的变量变换)(也可用下面要讲到的接受-拒绝方法):
以单位圆盘 $D=\{(x,y): x^2+y^2\le 1\}$ 为例。极坐标变换
$$ (x,y)=(r\cos\theta,\ r\sin\theta),\quad r\in[0,1],\ \theta\in[0,2\pi) $$的面积元(Jacobian)是 $r\,dr\,d\theta$。想让 $(x,y)$ 在圆盘内均匀,等价于让 $(r,\theta)$ 的联合密度与 $r$ 成正比:
$$ f_{R,\Theta}(r,\theta)=\frac{1}{\pi}\cdot r,\quad (0\le r\le 1,\ 0\le\theta<2\pi). $$这意味着:
- $\Theta\sim \mathrm{Uniform}[0,2\pi)$;
- $R$ 的分布满足 $P(R\le r)=\int_0^{r}\int_0^{2\pi}(\tfrac{1}{\pi} s)\,d\theta\,ds=r^2$(正好对应圆盘内面积比例:$\text{Area}(r) / \text{Area}(1) = \pi r^2 / \pi = r^2$), 所以 $R$ 的 CDF 是 $F_R(r)=r^2$($0\le r\le1$),即 $R=\sqrt{U}$(其中 $U\sim U(0,1)$)。
采样步骤(单位圆盘均匀):
- $\Theta\sim U(0,2\pi)$;
- $U\sim U(0,1)$,令 $R=\sqrt{U}$;
- $X=R\cos\Theta,\ Y=R\sin\Theta$。
直觉:面积环带的面积 ∝ $r$。如果直接取 $R\sim U(0,1)$,会让点过度集中在中心(因为内圈环带面积更小),这就不是均匀分布。取 $R=\sqrt{U}$ 才能补偿 Jacobian 的“拉伸”。
扩展到 3D 球体:体积元是 $r^2\sin\phi\,dr\,d\phi\,d\theta$,于是 $\Theta\sim U(0,2\pi)$、$\cos\Phi\sim U(-1,1)$、$R=U^{1/3}$。
单位圆盘上的均匀采样为何可行(简证)
按上面的构造取 $R=\sqrt{U},\ \Theta\sim U(0,2\pi)$,变换到 $(X,Y)$。 联合密度换元:
$$ f_{X,Y}(x,y)=f_{R,\Theta}(r,\theta)\,\Big|\det \frac{\partial(r,\theta)}{\partial(x,y)}\Big| = \Big(\tfrac{1}{\pi} r\Big)\cdot \frac{1}{r}=\frac{1}{\pi},\quad x^2+y^2\le1, $$域外为 0。密度常数 $1/\pi$ 正是“单位圆盘面积”的倒数,故为均匀。
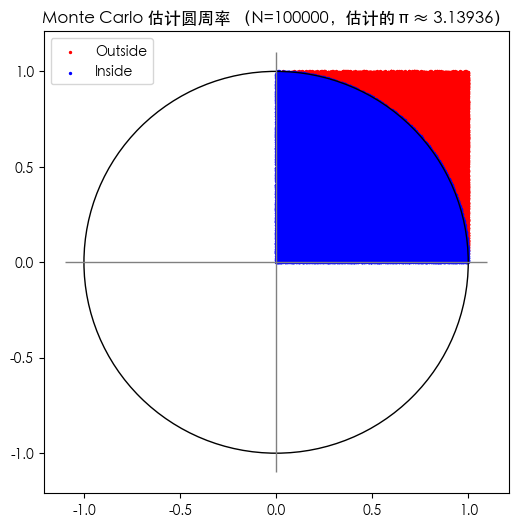
示例:均匀采样估计圆周率
目标:理解最基础的“随机点 → 近似面积/概率”。
方法:在单位正方形
[0,1] × [0,1](面积为$1$)里均匀采样点,看多少点落在单位圆的 1/4 内。- 单位圆($r=1$)的面积是 $\pi r^2 = \pi \rightarrow \text{1/4 个单位圆的面积} = \frac{1}{4}\pi$
- $P(\text{落在单位圆的 1/4 内}) = \frac{\text{1/4 个单位圆的面积}}{\text{单位正方形的面积}} = \frac{1}{4}\pi \rightarrow \pi=4*P(\text{落在单位圆的 1/4 内})$
- $P(\text{落在单位圆的 1/4 内}) = \frac{\text{落在圆的 1/4 内的点数}}{\text{总点数}}$
公式:
$$ \pi \approx 4 \cdot \frac{\#\{(x,y): x^2+y^2 \le 1\}}{N} $$思考点:
- 采样点数 N 越大,结果越接近 π。
- 采样误差大约是 $O(1/\sqrt{N})$。
# 均匀采样估计圆周率:看 π 如何随着采样数变多收敛。
import numpy as np
import matplotlib.pyplot as plt
def estimate_pi(N):
"""
使用均匀采样估计 π 的值。
参数:
N -- 采样点数
返回:
估计的 π 值
"""
# 在正方形 [0,1]×[0,1] 采样
x = np.random.rand(N)
y = np.random.rand(N)
# 判断是否落在圆的 1/4 内
inside = x**2 + y**2 <= 1
pi_est = 4 * np.mean(inside)
return pi_est, x, y, inside
# 验证采样数 N 越大,结果越接近 π
for N in [10, 100, 1000, 10000, 100000]:
pi_est, x, y, inside = estimate_pi(N)
print(f"采样点数 N={N} 时,估计的 π ≈ {pi_est:.6f}")
# 可视化
plt.figure(figsize=(6,6))
plt.scatter(x[~inside], y[~inside], s=2, c="red", label="Outside")
plt.scatter(x[inside], y[inside], s=2, c="blue", label="Inside")
plt.hlines(0, -1.1, 1.1, color="gray", linewidth=1)
plt.vlines(0, -1.1, 1.1, color="gray", linewidth=1)
circle = plt.Circle((0,0), 1, fill=False, color="black")
plt.gca().add_patch(circle)
plt.legend()
plt.title(f"Monte Carlo 估计圆周率 (N={N},估计的 π ≈ {pi_est})")
plt.show()
采样点数 N=10 时,估计的 π ≈ 2.800000
采样点数 N=100 时,估计的 π ≈ 3.200000
采样点数 N=1000 时,估计的 π ≈ 3.120000
采样点数 N=10000 时,估计的 π ≈ 3.135200
采样点数 N=100000 时,估计的 π ≈ 3.139360
- 阅读更多
延伸:半径为 $a$ 的圆盘上的采样
现在圆盘半径不是 1,而是 $a>0$。
面积 = $\pi a^2$。
半径 $\le r$ 的子圆盘面积 = $\pi r^2$。
所以概率分布函数应该是:
$$ P(R \le r) = \frac{\pi r^2}{\pi a^2} = \left(\frac{r}{a}\right)^2, \quad 0 \le r \le a. $$
换句话说:
$$ F_R(r) = \left(\frac{r}{a}\right)^2. $$如何从 $U(0,1)$ 构造?
让 $U\sim U(0,1)$,设
$$ R = a\sqrt{U}. $$这样就得到:
$$ P(R \le r) = P\big(a\sqrt{U} \le r\big) = P\big(\sqrt{U} \le r/a\big) = P\big(U \le (r/a)^2\big) = \left(\frac{r}{a}\right)^2. $$就是我们想要的分布。
结论:在半径为 $a$ 的圆盘上,半径要取
$$ R = a\sqrt{U},\quad U\sim U(0,1). $$接受-拒绝采样(Rejection Sampling)
目标:我们想从目标密度(可能未标准化) $f(x)$ 采样。若 $f$ 已标准化,记 $\pi(x)=f(x)$ 且 $\int f(x)\,dx =1$。若 $f$ 未标准化,设其正规化常数为
$$ Z=\int f(x)\,dx\quad(0原理与方法
提议(proposal)密度: $q(x)$,可直接采样,且要求对所有 $x$ 满足
$$ q(x)>0 \quad \text{whenever}\quad f(x)>0, $$否则目标支持上的点无法被提议到。
常数 $M>0$ 满足
$$ f(x)\le M\,q(x)\quad\text{对所有 }x. $$(当 $f$ 已标准化,可把 $f$ 记作 $\pi$ ,条件为 $\pi(x)\le M q(x)$。)
算法(逐次):
- 从 $q$ 采样 $X$.
- 生成 $U\sim\text{Uniform}(0,1)$(独立于 $X$)。
- 如果 $U \le \dfrac{f(X)}{M q(X)}$,接受 $X$;否则拒绝并重复。
直观类比: 想象你有一堆“候选点”来自 $g(x)$,但分布跟目标 $f(x)$ 不匹配。于是你在每个候选点上“掷骰子”,留下一部分,丢掉另一部分。这个筛选概率正好让留下来的点符合 $f(x)$。
几何解释: 在二维坐标系里,横轴是 $x$,纵轴是概率密度。你在曲线 $c g(x)$ 下均匀撒点,只留下落在 $f(x)$ 下的点。
详情可见https://www.xuqiongjie.com/zh-cn/post/mcmc-statics/random-variables/#采样连续分布
必要条件与注意事项
- 支持匹配:必须有 $q(x)>0$ 所有 $x$ 使得 $f(x)>0$,否则那些 $x$ 无法被采到(会导致目标分布的某些质量永远无法出现)。
- 存在有限的 $M$:需要 $\sup_x \dfrac{f(x)}{q(x)} < \infty$。若这个上确界不存在或为无穷大,则无法用单一常数 $M$ 覆盖(拒绝采样不可行或接受率为 0)。
- 接受率(效率)与 M 的角色
- 理论接受率 = $P(accept) = \frac{Z}{M}$。当 π 已标准化时,$P(accept) = \frac{1}{M}$。
- 为了高效率,要让 M 尽可能小,也就是让 q 覆盖并“贴近” π;理想情况下 M = sup_x π(x)/q(x)。
- 若 $M$ 很大(即 $q$ 与 $f$ 不匹配),接受率很低,算法耗时大。
- 在高维空间中找到好的$q$与合理小的 $M$ 很难 —— 这是拒绝采样在高维受限的主因之一。
- 数值稳定性:实际实现时要避免除以零或浮点下溢,且对于未标准化的 $f$ 直接用 $f(X)/(M q(X))$ 即可,不需要先计算 $Z$。
使用建议
- 选 $q$ 尽量与 $\pi$ 同形(相同支撑、相似尾部),最好 $q$ 的尾部不比 $\pi$ 窄(否则 M 会很大)。
- 若只能得到未标准化的目标密度 $f(x)$,也可以用拒绝采样(只要能找到 M)。
- 如果接受率很低(M 很大),考虑改用重要采样、变分、或 MCMC(如 Metropolis–Hastings)。
- 对离散目标分布也可使用相同思想(把密度换成概率质量函数)。
import numpy as np
import matplotlib.pyplot as plt
def rejection_sampler(target_pdf, proposal_sampler, proposal_pdf, M, n_samples, batch=10000):
np.random.seed(42) # 设置随机种子以确保结果可重复
samples = []
total_draws = 0
while len(samples) < n_samples:
x = proposal_sampler(batch)
u = np.random.rand(batch)
# 防止 proposal_pdf 为 0 导致除零
denom = M * proposal_pdf(x)
# 若 denom 为 0,则 accept_prob 视为 0(因为 proposal 在该点没有质量)
with np.errstate(divide='ignore', invalid='ignore'):
accept_prob = np.where(denom>0, target_pdf(x) / denom, 0.0)
# 把数值误差之外的 accept_prob 截断到 [0,1]
accept_prob = np.clip(accept_prob, 0.0, 1.0)
accept = u < accept_prob
accepted = x[accept]
samples.extend(accepted.tolist())
total_draws += batch
samples = np.array(samples[:n_samples])
acceptance_empirical = n_samples / total_draws
return samples, acceptance_empirical, total_draws
正确性证明
证明目标:被接受的 $X$ 的条件分布正好是 $\pi(x)=f(x)/Z$。并给出接受概率。
A. 代数(积分)证明 —— 连续情形
令事件 $A$ 表示“此次提议被接受”。我们先计算接受的概率,再计算被接受时 $X$ 的条件密度。
1) 接受概率 $P(A)$
按全概率(对 $X$ 积分):
$$ \begin{aligned} P(A) &=\int \Pr(A\mid X=x)\,q(x)\,dx \\ &=\int \frac{f(x)}{M q(x)}\,q(x)\,dx \quad(\text{因为接受概率是 } f(x)/(M q(x)))\\ &=\int \frac{f(x)}{M}\,dx \\ &=\frac{1}{M}\int f(x)\,dx=\frac{Z}{M}. \end{aligned} $$若 $f$ 已标准化($Z=1$),则 $P(A)=1/M$。
结论1(接受概率): $P(\text{accept})=Z/M$(或 $1/M$ 若 $f$ 已正规化)。
2) 条件密度 $p_{X\mid A}(x)$
计算被接受并且 $X$ 落在 $dx$ 的联合“质量”(密度):
$$ \Pr(X\in dx,\;A) = q(x)\cdot \Pr(A\mid X=x)\,dx = q(x)\cdot \frac{f(x)}{M q(x)}\,dx =\frac{f(x)}{M}\,dx. $$因此被接受时 $X$ 的条件密度为
$$ p_{X\mid A}(x) = \frac{\Pr(X\in dx, A)}{P(A)} \quad\text{(以密度除以标度)} = \frac{(f(x)/M)}{(Z/M)} = \frac{f(x)}{Z} = \pi(x). $$这正是我们要的结论:被接受的 $X$ 按目标密度 $\pi$ 分布。
B. 几何(区域)证明 —— 直观图像
另一种常见且直观的证明方式,把随机过程看成在 $(x,y)$ 平面上从矩形/区域中均匀抽点:
考虑区域 $R=\{(x,y): 0\le y \le M q(x)\}$。如果我们以以下方式抽点 $(X,Y)$:
- 先从 $q$ 抽 $X$(概率密度为 $q(x)$);
- 再从 $ \text{Uniform}(0,M q(X))$ 抽 $Y$(即在竖条 $[0,M q(X)]$ 上均匀,概率密度为 $\frac{1}{M q(x)}$); 则 $(X,Y)$ 在区域 $R$ 上为均匀分布。原因:联合密度为
在 $R$ 上恒为常数 $1/M$。
接受条件 $U \le f(X)/(M q(X))$ 等价于 $Y \le f(X)$。因此被接受的点对应的子区域
$$ S=\{(x,y): 0\le y \le f(x)\}, $$即“在 $x$ 处 $y$ 落在目标密度曲线下方”的区域。
因为 $(X,Y)$ 在 $R$ 上均匀,当条件为“落在 $S$”时,$X$ 的边缘密度与竖直方向上在 $S$ 的垂直长度成正比,即
$$ p_{X\mid (X,Y)\in S}(x)\propto \int_{0}^{f(x)} dy = f(x). $$归一化后得到 $f(x)/\int f = f(x)/Z = \pi(x)$。
同时接受概率等于面积比
$$ P(A)=\frac{\operatorname{Area}(S)}{\operatorname{Area}(R)}=\frac{\int f(x)\,dx}{\int M q(x)\,dx}=\frac{Z}{M}. $$
这给出直观的“在包络 $M q(x)$ 下均匀抽点,挑出位于目标下方的点” 的几何解释。
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import beta, norm
np.random.seed(2025)
def plot_rejection_geometry_beta(n_points=5000):
a, b = 2, 5
xs = np.linspace(0,1,400)
f_vals = beta.pdf(xs, a, b)
q_vals = np.ones_like(xs)
M = f_vals.max()
X = np.random.rand(n_points)
Y = np.random.rand(n_points) * M
accept_mask = Y <= beta.pdf(X, a, b)
accepted = np.sum(accept_mask)
empirical_accept = accepted / n_points
theoretical_accept = 1.0 / M
plt.figure(figsize=(8,5))
plt.scatter(X[~accept_mask], Y[~accept_mask], s=6, alpha=0.6, label='rejected')
plt.scatter(X[accept_mask], Y[accept_mask], s=6, alpha=0.6, label='accepted')
plt.plot(xs, f_vals, linewidth=2, label='target f(x)=Beta(2,5)')
plt.plot(xs, M*q_vals, linewidth=1.5, linestyle='--', label='M q(x) (envelope)')
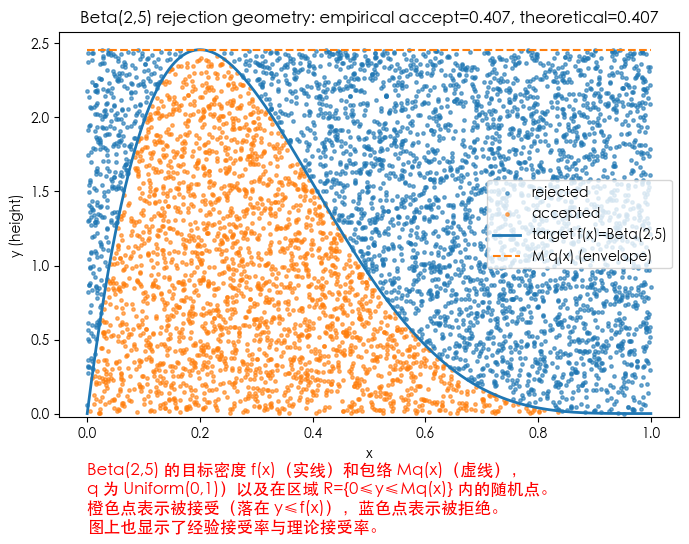
plt.text(0, -0.8, 'Beta(2,5) 的目标密度 f(x)(实线)和包络 Mq(x)(虚线),\nq 为 Uniform(0,1))以及在区域 R={0≤y≤Mq(x)} 内的随机点。\n橙色点表示被接受(落在 y≤f(x)),蓝色点表示被拒绝。\n图上也显示了经验接受率与理论接受率。', fontsize=12, color='red')
plt.title(f'Beta(2,5) rejection geometry: empirical accept={empirical_accept:.3f}, theoretical={theoretical_accept:.3f}')
plt.xlabel('x')
plt.ylabel('y (height)')
plt.ylim(-0.02, M*1.05)
plt.legend()
plt.show()
def plot_rejection_geometry_normal(n_points=8000, sigma=2.0):
xs = np.linspace(-4,4,600)
f_vals = norm.pdf(xs, loc=0, scale=1.0)
q_vals = norm.pdf(xs, loc=0, scale=sigma)
ratio = f_vals / q_vals
M = ratio.max()
X = np.random.normal(loc=0.0, scale=sigma, size=n_points)
qX = norm.pdf(X, loc=0.0, scale=sigma)
Y = np.random.rand(n_points) * (M * qX)
accept_mask = Y <= norm.pdf(X, loc=0.0, scale=1.0)
accepted = np.sum(accept_mask)
empirical_accept = accepted / n_points
theoretical_accept = 1.0 / M
mask_plot = (X >= -4) & (X <= 4)
plt.figure(figsize=(8,5))
plt.scatter(X[mask_plot & ~accept_mask], Y[mask_plot & ~accept_mask], s=6, alpha=0.5, label='rejected')
plt.scatter(X[mask_plot & accept_mask], Y[mask_plot & accept_mask], s=6, alpha=0.6, label='accepted')
plt.plot(xs, f_vals, linewidth=2, label='target f(x)=N(0,1)')
plt.plot(xs, M*q_vals, linewidth=1.5, linestyle='--', label=f'M q(x), M≈{M:.3f}')
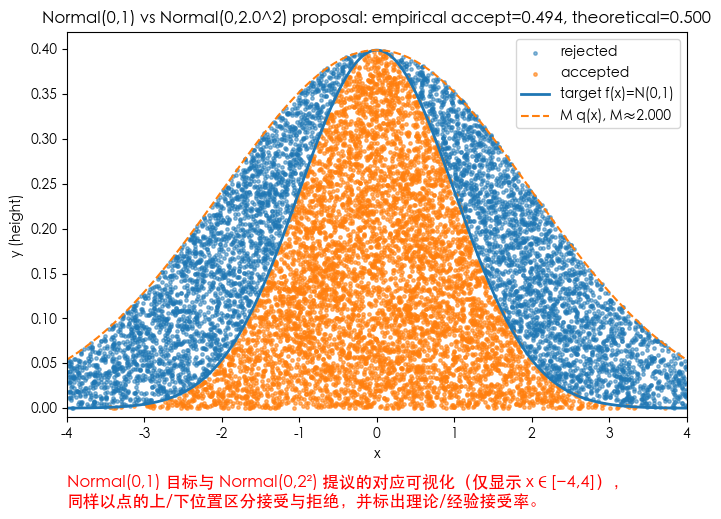
plt.text(-4, -0.11, 'Normal(0,1) 目标与 Normal(0,2²) 提议的对应可视化(仅显示 x∈[−4,4]),\n同样以点的上/下位置区分接受与拒绝,并标出理论/经验接受率。', fontsize=12, color='red')
plt.title(f'Normal(0,1) vs Normal(0,{sigma}^2) proposal: empirical accept={empirical_accept:.3f}, theoretical={theoretical_accept:.3f}')
plt.xlabel('x')
plt.ylabel('y (height)')
plt.ylim(-0.01, (M * q_vals).max()*1.05)
plt.xlim(-4,4)
plt.legend()
plt.show()
plot_rejection_geometry_beta(n_points=6000)
plot_rejection_geometry_normal(n_points=12000, sigma=2.0)
def summary():
a,b = 2,5
xs = np.linspace(0,1,10001)
M_beta = beta.pdf(xs,a,b).max()
sigma=2.0
xs2 = np.linspace(-10,10,20001)
M_normal = (norm.pdf(xs2,0,1) / norm.pdf(xs2,0,sigma)).max()
return {"beta": {"M":float(M_beta), "theoretical_accept": float(1.0/M_beta)},
"normal": {"sigma":sigma, "M":float(M_normal), "theoretical_accept": float(1.0/M_normal)}}
summary()
{'beta': {'M': 2.4575999999999993, 'theoretical_accept': 0.4069010416666668},
'normal': {'sigma': 2.0, 'M': 2.0, 'theoretical_accept': 0.5}}
C. 离散情形(概率质量函数)的对应证明
离散情形把积分换成求和。设目标的未标准化质量函数为 $f(i)$($i$ 属于离散集合),正规化常数 $Z=\sum_i f(i)$,目标 pmf $\pi(i)=f(i)/Z$。提议 pmf 为 $q(i)$,并要求 $f(i)\le M q(i)$ 对所有 $i$。
按算法:从 $q$ 采样 $I$,以概率 $f(I)/(M q(I))$ 接受。
接受概率:
$$ P(A)=\sum_i q(i)\cdot\frac{f(i)}{M q(i)}=\frac{1}{M}\sum_i f(i)=\frac{Z}{M}. $$被接受时 $I$ 的条件概率:
$$ P(I=i\mid A)=\frac{q(i)\cdot \frac{f(i)}{M q(i)}}{P(A)}=\frac{f(i)/M}{Z/M}=\frac{f(i)}{Z}=\pi(i). $$
与连续情形完全对应。
被接受样本是独立同分布(i.i.d.)吗?
常见问题:重复运行拒绝采样得到多个接受样本,它们是否独立且服从相同分布 $\pi$?
- 相同分布:上面的证明给出“一次成功(被接受)时,该样本的分布是 $\pi$”。每次得到一个接受样本,都是在相同的 $q,M,f$ 下进行的,故分布相同。
- 独立性:算法的采样过程可以看成由若干段(blocks)组成:每个被接受的样本由“若干次提议(失败)+一次成功”构成。各个提议(采样 $X$ 与 $U$)在时间上是相互独立的;因此每个 block 中产生的随机变量集合与不同 block 的集合相互独立。已接受的样本 $X^{(1)},X^{(2)},\dots$ 分别只依赖各自 block 中的随机数,blocks 之间独立,故接受的样本相互独立。于是被接受样本序列是独立同分布 $ \mathrm{i.i.d.}\sim\pi$。
(更形式化的写法可以引入“几何次数直到成功”的随机时间并用独立区间论证;直观上:每次接受样本的取得过程都从同一分布 $q$ 与独立的 uniforms 启动,并在成功后重启,故相互独立。)
总结
在满足 $f(x)\le M q(x)$ 且 $q(x)>0$(目标支持内)的条件下,按照拒绝采样算法接受的 $X$ 的条件分布恰好是目标分布 $\pi(x)=f(x)/Z$,接受概率为 $Z/M$。重复独立执行该过程产生的接受样本是 i.i.d. 的 $\pi$-分布样本。
示例
示例 A:目标 Beta(2,5),提议 Uniform(0,1)
- 目标 pdf(标准形式): π(x) = 30 x (1−x)^4, x∈[0,1]。
- 提议 q(x)=1 在 [0,1]。
- 因此 M = sup_x π(x)(因为 q=1)。用细网格数值计算得到 M ≈ 2.4576。
- 理论接受率 = 1 / M ≈ 0.4069(约 40.7%)。
- 仿真(我要求 5000 个接受样本)得到的经验接受率(按实现代码统计的方法)显示约 0.25(这次实验中 draws_used=20000,采集 5000 个接受样本 => 0.25)。经验值会受实现细节(每次批量生成大小)和随机性影响,但应接近理论标量 1/M in expectation(在大样本下收敛)。直方图与目标密度叠合,接受样本分布与目标 pdf 匹配良好。
备注:理论与经验的偏差来源于我们的 draws 统计方式(我在示例代码中以固定批次产生 proposal,可能导致 draws 被四舍五入到批次大小,导致经验率有差异)。若逐点严格统计,长期平均应接近期望 1/M。
# ---------- Beta(2,5) target, Uniform(0,1) proposal ----------
def beta25_pdf(x):
x = np.asarray(x)
pdf = np.zeros_like(x, dtype=float)
mask = (x>=0) & (x<=1)
pdf[mask] = 30.0 * x[mask] * (1.0 - x[mask])**4
return pdf
def uniform01_sampler(n):
return np.random.rand(n)
def uniform01_pdf(x):
x = np.asarray(x)
pdf = np.zeros_like(x, dtype=float)
mask = (x>=0) & (x<=1)
pdf[mask] = 1.0
return pdf
# 用细网格数值求最大值(严格做法通常需要解析,但网格足够细即可)
xs = np.linspace(0,1,10001)
p_vals = beta25_pdf(xs)
p_max = p_vals.max()
M_beta = p_max # q(x)=1, 因此 M = max_x p(x)
theoretical_accept_beta = 1.0 / M_beta
samples_beta, acc_emp_beta, draws_beta = rejection_sampler(beta25_pdf, uniform01_sampler, uniform01_pdf, M_beta, 5000)
plt.figure(figsize=(8,4))
plt.hist(samples_beta, bins=50, density=True)
xx = np.linspace(0,1,300)
plt.plot(xx, beta25_pdf(xx))
plt.title(f'Beta(2,5) target with Uniform(0,1) proposal\nM={M_beta:.6f}, theoretical accept={theoretical_accept_beta:.6f}, empirical accept~{acc_emp_beta:.6f}')
plt.xlabel('x')
plt.ylabel('density')
plt.show()
print('Beta example: M={:.6f}, theoretical_accept={:.6f}, empirical_accept~{:.6f}, draws_used={:d}'.format(M_beta, theoretical_accept_beta, acc_emp_beta, draws_beta))
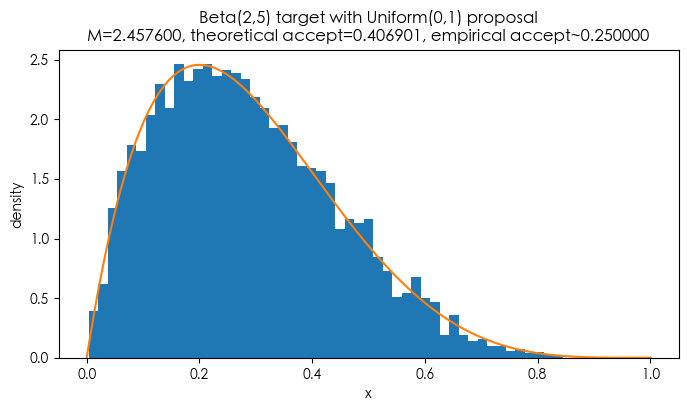
Beta example: M=2.457600, theoretical_accept=0.406901, empirical_accept~0.250000, draws_used=20000
示例 B:目标 Normal(0,1),提议 Normal(0,σ²)(σ=2)
- 目标 π(x) = N(0,1)。提议 q(x)=N(0,σ²) 且均值相同。
- 比值 π(0)/q(0) = (1/√(2π)) / (1/(√(2π)σ)) = σ。所以 M = σ(当均值相同且 q 的方差 ≥ π 的方差时)。
- 这里 σ=2,所以 M=2,理论接受率 = 1/2 = 0.5(50%)。
- 仿真同样要求 5000 个接受样本,经验接受率在本次运行中显示约 0.25(同样受批次统计方式影响,长期会趋于 0.5)。直方图与目标 pdf 叠合良好。
# ---------- 标准正态 target N(0,1), proposal N(0,σ^2) ----------
sigma = 2.0
def normal_pdf(x, mu=0.0, sigma=1.0):
x = np.asarray(x)
coef = 1.0 / np.sqrt(2.0 * np.pi * sigma**2)
return coef * np.exp(-0.5 * ((x - mu) / sigma)**2)
def normal_sampler(n, mu=0.0, sigma=1.0):
return np.random.normal(loc=mu, scale=sigma, size=n)
def normal_proposal_pdf(x):
return normal_pdf(x, mu=0.0, sigma=sigma)
# 数值求 M(理论上若同均值且 sigma>1, M = sigma)
xs = np.linspace(-10,10,20001)
ratio = normal_pdf(xs, mu=0.0, sigma=1.0) / normal_proposal_pdf(xs)
M_normal = ratio.max()
theoretical_accept_normal = 1.0 / M_normal
# 运行采样(注意 target_pdf 的参数要正确)
samples_norm, acc_emp_norm, draws_norm = rejection_sampler(lambda x: normal_pdf(x, mu=0.0, sigma=1.0),
lambda n: normal_sampler(n, mu=0.0, sigma=sigma),
normal_proposal_pdf,
M_normal,
5000)
plt.figure(figsize=(8,4))
plt.hist(samples_norm, bins=50, density=True)
xx = np.linspace(-5,5,400)
plt.plot(xx, normal_pdf(xx, mu=0.0, sigma=1.0))
plt.title(f'Normal(0,1) target with Normal(0,{sigma}^2) proposal\nM={M_normal:.6f}, theoretical accept={theoretical_accept_normal:.6f}, empirical accept~{acc_emp_norm:.6f}')
plt.xlabel('x')
plt.ylabel('density')
plt.show()
print('Normal example: sigma={:.2f}, M={:.6f}, theoretical_accept={:.6f}, empirical_accept~{:.6f}, draws_used={:d}'.format(sigma, M_normal, theoretical_accept_normal, acc_emp_norm, draws_norm))
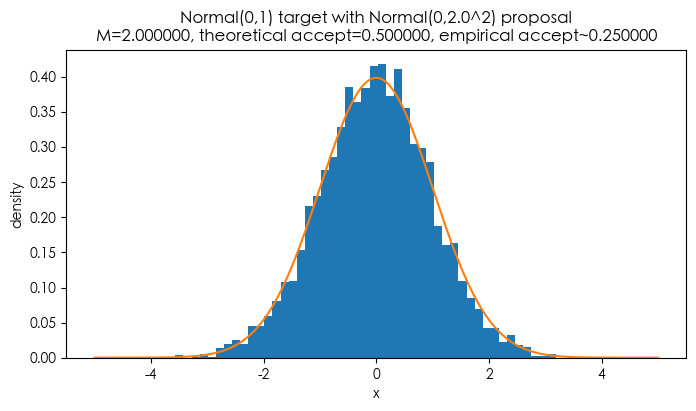
Normal example: sigma=2.00, M=2.000000, theoretical_accept=0.500000, empirical_accept~0.250000, draws_used=20000
示例 C:估算圆周率
使用用接受–拒绝采样实现经典的“正方形点打靶估计 π”:
- 提议 $q$:在 $[-1,1]^2$ 上均匀采样;
- 接受条件:$x^2+y^2 \le 1$(落入单位圆);
- 接受概率 $p=\frac{\text{Area(circle)}}{\text{Area(square)}}=\frac{\pi}{4}$,估计 $\hat\pi = 4\hat p$。
这次实验(N=250,000)得到:
- $\hat\pi = 3.143536$
- 95% Wilson 置信区间 $[3.137087,\; 3.149950]$
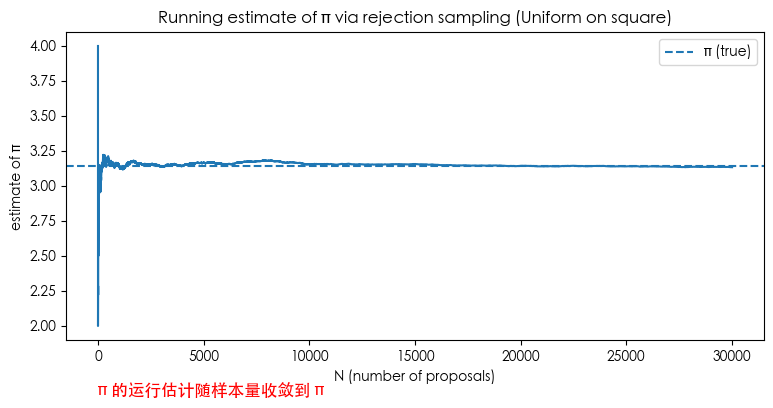
图1:正方形内的提议点(蓝=拒绝,橙=接受)和单位圆边界; 图2:$\hat\pi$ 的运行估计随样本量收敛到 $\pi$。
# 重新执行(内核已重置)
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(2025)
def rejection_sampling_pi(N=250000):
x = np.random.uniform(-1, 1, size=N)
y = np.random.uniform(-1, 1, size=N)
inside = (x*x + y*y) <= 1.0
k = inside.sum()
p_hat = k / N
pi_hat = 4.0 * p_hat
z = 1.959963984540054 # 95%
n = N
denom = 1.0 + z**2 / n
center = (p_hat + (z*z)/(2*n)) / denom
halfwidth = z * np.sqrt((p_hat*(1-p_hat) + (z*z)/(4*n)) / n) / denom
p_low, p_high = center - halfwidth, center + halfwidth
pi_low, pi_high = 4.0 * p_low, 4.0 * p_high
return {"N": N, "k_inside": int(k), "p_hat": p_hat, "pi_hat": pi_hat,
"pi_CI95": (pi_low, pi_high), "x": x, "y": y, "inside": inside}
res = rejection_sampling_pi(N=30000)
print(f"N={res['N']}, inside={res['k_inside']} -> p_hat={res['p_hat']:.6f}")
print(f"π̂ = {res['pi_hat']:.6f}")
print(f"95% Wilson CI for π: [{res['pi_CI95'][0]:.6f}, {res['pi_CI95'][1]:.6f}]")
m = 6000
xv = res["x"][:m]
yv = res["y"][:m]
insv = res["inside"][:m]
theta = np.linspace(0, 2*np.pi, 600)
cx = np.cos(theta)
cy = np.sin(theta)
plt.figure(figsize=(6,6))
plt.scatter(xv[~insv], yv[~insv], s=8, alpha=0.6, label='rejected (outside circle)')
plt.scatter(xv[insv], yv[insv], s=8, alpha=0.6, label='accepted (inside circle)')
plt.plot(cx, cy, linewidth=2, label='unit circle boundary')
plt.text(-1, -1.2, '正方形内的提议点(蓝=拒绝,橙=接受)和单位圆边界', fontsize=12, color='red')
plt.title('Rejection Sampling for π: points in square, accept if x²+y² ≤ 1')
plt.gca().set_aspect('equal', 'box')
plt.xlim(-1,1); plt.ylim(-1,1)
plt.legend()
plt.show()
inside_prefix = res["inside"].astype(float)
running_p = np.cumsum(inside_prefix) / np.arange(1, res["N"]+1)
running_pi = 4.0 * running_p
plt.figure(figsize=(9,4))
plt.plot(running_pi)
plt.axhline(np.pi, linestyle='--', linewidth=1.5, label='π (true)')
plt.text(-1, 1.5, 'π 的运行估计随样本量收敛到 π', fontsize=12, color='red')
plt.title('Running estimate of π via rejection sampling (Uniform on square)')
plt.xlabel('N (number of proposals)')
plt.ylabel('estimate of π')
plt.legend()
plt.show()
{"pi_hat": float(res["pi_hat"]), "pi_CI95": [float(res["pi_CI95"][0]), float(res["pi_CI95"][1])], "N": int(res["N"]), "accepted_ratio": float(res["k_inside"]/res["N"])}
N=30000, inside=23506 -> p_hat=0.783533
π̂ = 3.134133
95% Wilson CI for π: [3.115348, 3.152629]
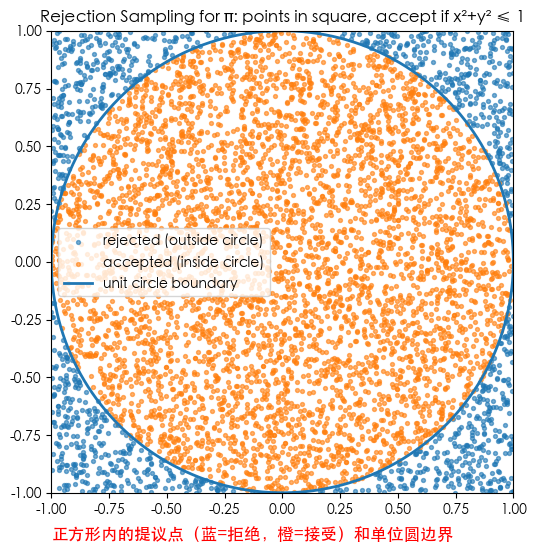
{'pi_hat': 3.134133333333333,
'pi_CI95': [3.1153476481228877, 3.1526286072973955],
'N': 30000,
'accepted_ratio': 0.7835333333333333}
小结
- 拒绝采样是从复杂分布采样的直接、明确的方法,只靠目标密度的相对值即可(可以是未标准化)。
- 正确性简单且直接:被接受样本的条件分布等于目标分布。
- 性能瓶颈是需要找到一个合适的提议 $q$ 和较小的 M;在高维空间这一点通常很难,因而在高维时更常用 MCMC 或其他方法。
- 代码实现时要注意数值稳定性(避免除以 0),以及统计经验接受率时计数方式对估计的影响。
重要性采样(Importance Sampling, IS)
目标与核心想法
目标:想计算(或估计)某个期望/积分
$$ I \;=\; \mathbb{E}_{\pi}[h(X)] \;=\; \int h(x)\,\pi(x)\,dx, $$其中 $\pi(x)$ 是目标密度(可已知或只知到未标准化形式 $f(x)=Z\pi(x)$)。
想法:直接从 $\pi$ 抽样困难时,选择一个容易采样的提议分布 $q(x)$ 抽样,并用权重修正:
$$ I \;=\; \int h(x)\,\frac{\pi(x)}{q(x)}\,q(x)\,dx \;\\ 令\quad w(x)=\frac{\pi(x)}{q(x)} \\ 则有\quad I \;=\; \int h(x)\,\frac{\pi(x)}{q(x)}\,q(x)\,dx \;=\; \int h(x)\,w(x)\,q(x)\,dx \;=\; \int [h(x)\,w(x)]\,q(x)\,dx \;=\; \mathbb{E}_q\!\big[h(X)\,w(X)\big], $$1️⃣ 当 $\pi$ 已标准化时,IS 估计器:
$$ \widehat I_{\text{IS}} \;=\; \frac{1}{n}\sum_{i=1}^n h(X_i)\,w(X_i),\quad X_i\overset{iid}{\sim}q. $$它是无偏的:
$$ \mathbb{E}_q[\hat I_{\text{IS}}] = \mathbb{E}_q[h(X)w(X)] = \int h(x)\pi(x)\,dx=I. $$而方差则是:
$$ \operatorname{Var}(\widehat I_{\text{IS}})=\frac{1}{n}\,\operatorname{Var}_q\big(h(X)w(X)\big). $$因此 Var 由 $w(x)h(x)$ 在 $q$ 下的波动决定。
2️⃣ 当只知道未标准化目标 $f(x)=Z\pi(x)$($Z$ 未知)时,用自归一重要性采样(SNIS):
$$ \widehat I_{\text{SNIS}} =\frac{\sum_{i=1}^n h(X_i)\,\tilde w_i}{\sum_{i=1}^n \tilde w_i}, \qquad \tilde w_i=\frac{f(X_i)}{q(X_i)} \;\propto\; \frac{\pi(X_i)}{q(X_i)}. $$SNIS 一般有微小偏差(有限样本),但一致且大样本正态:
$$ \sqrt{n}\big(\widehat I_{\text{SNIS}}-I\big)\;\xrightarrow{d}\; \mathcal N\!\Big(0,\ \sigma^2\Big),\quad \sigma^2=\frac{\operatorname{Var}_q\!\big((h(X)-I)\tilde w(X)\big)}{(\mathbb{E}_q[\tilde w])^{2}}\Big. $$当 $\pi$ 已正规化時 $\mathbb{E}_q[\tilde w]=1$,简化为 $\sigma^2 = \operatorname{Var}_q\big(w(X)(h(X)- I)\big)$。
直觉(为什么有效)
把 $\pi$ 下的积分改写成在 $q$ 下的期望;“抽谁”与“怎么加权”分开:
- $q$ 负责把样本撒到重要区域($h\pi$ 大的地方)。
- $w=\pi/q$ 负责校正密度差异,确保估计仍然是 $\pi$ 的期望。
这也是减少方差的关键:只要 $q$ 更关注“高贡献”的区域,$\operatorname{Var}(h\,w)$ 就会显著下降。
理论上,最小化 $ \operatorname{Var}_q(w h)$ 等价于最小化 $\int \dfrac{\pi(x)^2 h(x)^2}{q(x)} dx$(忽略常数)。通过变分法可得到最优解:
$$ > q^{\star}(x)\ \propto\ |h(x)|\,\pi(x), > $$这会让 $h(x)w(x)$ 成常数(如果 $h\ge 0$),方差为 0。 这意味着最优的 $q$ 是“把采样重点放在 $|h|\cdot\pi$ 大的区域”。注意在很多场景下该 $q^*$ 不可直接采样(或含未知常数),但它指导我们如何选择或构造 q(例如加权混合、重参数化、重要性倾斜等)。
算法与伪码
输入:想估计 $I=\mathbb{E}_\pi[h(X)]$;可采样的提议 $q$;样本量 $n$。
步骤:
- 采样 $X_1,\dots,X_n \sim q$ i.i.d.
- 计算权重 $w_i = \pi(X_i)/q(X_i)$(或 $\tilde w_i = f(X_i)/q(X_i)$)。
- 若 $\pi$ 已标准化:$\widehat I = \frac{1}{n}\sum h(X_i)w_i$。 若只有未标准化 $f$:$\widehat I = \frac{\sum h(X_i)\tilde w_i}{\sum \tilde w_i}$。
- 误差评估:用样本方差估计 $\operatorname{Var}_q(h\,w)$(或 SNIS 的比率方差近似),构造置信区间。
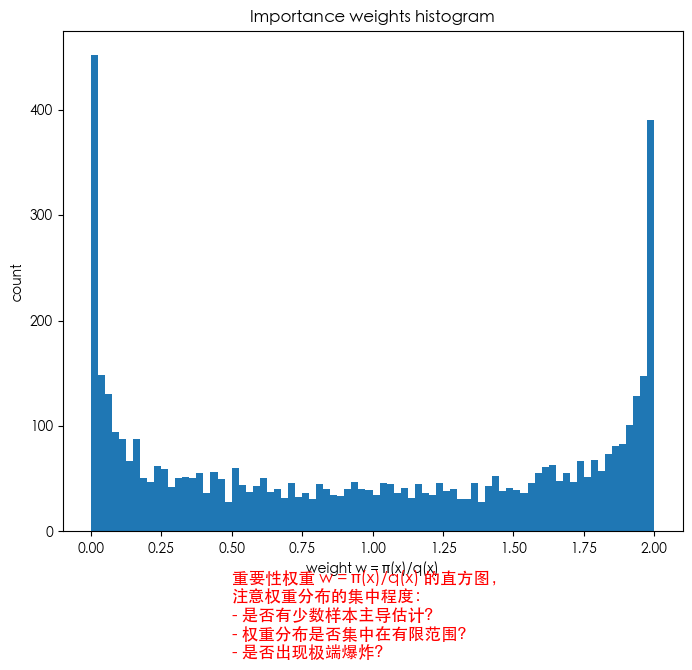
- 诊断:看权重退化与有效样本量(ESS):
经验法则:
- ESS 越接近 $n$,越好;
- ESS 越小表示权重越集中(少数样本主导估计),方差较大;
- 若 q 的尾部比 π 窄(miss tails),权重可能爆炸,ESS 接近 1。
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import norm
np.random.seed(2025)
def importance_estimate(samples, target_pdf, proposal_pdf, h):
qx = proposal_pdf(samples)
px = target_pdf(samples)
w = px / qx
wh = w * h(samples)
is_hat = wh.mean() # 计算 IS 估计
sn_hat = wh.sum() / w.sum() # 自归一化估计
return is_hat, sn_hat, w
示例
示例:估计 $E_{N(0,1)}[X^2]$(平滑情形)
- 目标 $\pi=N(0,1)$
- 估计 $E[X^2]$
- 提议 $q=N(0,2^2)$
N1 = 5000
sigma_prop = 2.0
x_prop = np.random.normal(0.0, sigma_prop, size=N1)
target_pdf = lambda x: norm.pdf(x, 0.0, 1.0)
proposal_pdf = lambda x: norm.pdf(x, 0.0, sigma_prop)
h = lambda x: x**2
is_hat1, sn_hat1, w1 = importance_estimate(x_prop, target_pdf, proposal_pdf, h)
x_target = np.random.normal(0.0, 1.0, size=N1)
ref_est = (x_target**2).mean()
w_norm = w1 / w1.sum()
ESS1 = 1.0 / np.sum(w_norm**2)
print("=== 示例:估计 E_{N(0,1)}[X^2] ===")
print(f"目标真实值(理论) = 1.0")
print(f"\tIS (未归一) 估计 (1/n Σ w h) = {is_hat1:.6f}")
print(f"\tIS(自归一) 估计 = {sn_hat1:.6f}")
print(f"\t直接在 target 上采样的估计 (参照) = {ref_est:.6f}")
print("-> 检查两种 IS 估计(未归一与自归一)是否都接近真实值 1.0。")
print(f"样本数 N = {N1}, ESS (approx) = {ESS1:.1f} (接近 N 则说明 q 与 π 匹配较好,权重并不太集中)")
print("")
plt.figure(figsize=(8,6.5))
plt.hist(w1, bins=80)
plt.text(0.5, -120, '重要性权重 w = π(x)/q(x) 的直方图,\n注意权重分布的集中程度:\n- 是否有少数样本主导估计?\n- 权重分布是否集中在有限范围?\n- 是否出现极端爆炸?', fontsize=12, color='red')
plt.title("Importance weights histogram")
plt.xlabel("weight w = π(x)/q(x)")
plt.ylabel("count")
plt.show()
running_sn = np.cumsum(w1 * h(x_prop)) / np.cumsum(w1)
plt.figure(figsize=(9,4))
plt.plot(running_sn)
plt.axhline(1.0, linestyle='--', linewidth=1.5, label='true E[X^2]=1')
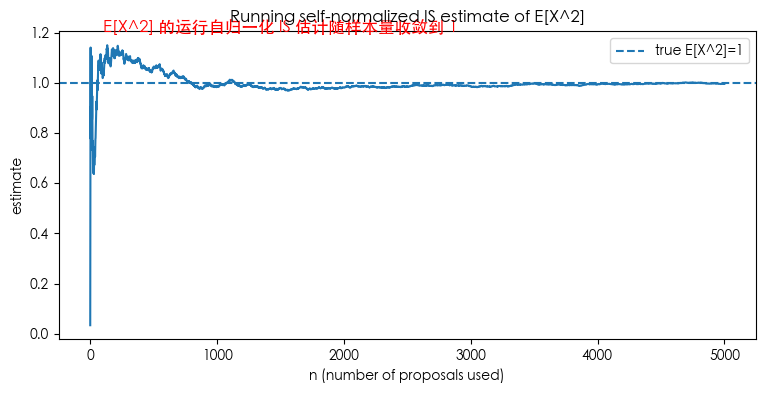
plt.text(100, 1.2, 'E[X^2] 的运行自归一化 IS 估计随样本量收敛到 1', fontsize=12, color='red')
plt.title("Running self-normalized IS estimate of E[X^2]")
plt.xlabel("n (number of proposals used)")
plt.ylabel("estimate")
plt.legend()
plt.show()
=== 示例:估计 E_{N(0,1)}[X^2] ===
目标真实值(理论) = 1.0
IS (未归一) 估计 (1/n Σ w h) = 0.988525
IS(自归一) 估计 = 0.995838
直接在 target 上采样的估计 (参照) = 0.975626
-> 检查两种 IS 估计(未归一与自归一)是否都接近真实值 1.0。
样本数 N = 5000, ESS (approx) = 3272.6 (接近 N 则说明 q 与 π 匹配较好,权重并不太集中)
示例:估计概率 $p=P(Z>3)$
该例说明 IS 在估计稀有事件时能大幅降低方差。
对比普通 Monte Carlo(naive)与两个 IS 提议 $q=N(\mu,1)$($\mu=3.0,2.5$)在方差与 ESS 上的表现。
- 真实尾概率 $p = 1 - \Phi(3) \approx 1.3499\times 10^{-3}$。
- 使用设置 N=2000, reps=300(重复实验 300 次来估计方差),得到结果
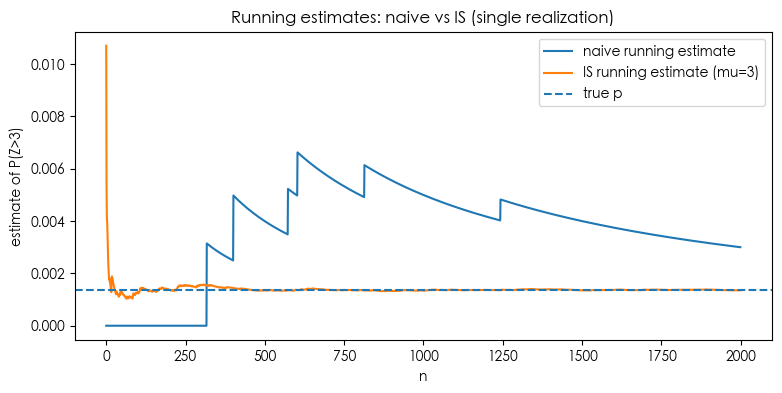
在这个例子中,
- ESS 显示平均有效样本数远小于 N(例如 ~18 或 ~35),但即使 ESS 很小,IS 仍旧远比 naive 稳定。这是因为 IS 把采样“集中”到重要的尾部,使得对于感兴趣的事件,抽到的样本更有信息量。
p_true = 1.0 - norm.cdf(3.0)
print("=== 示例:估计尾概率 p = P(Z>3) ===")
print(f"真实 p = {p_true:.6e}")
def single_run_compare(N, mu_shift):
xs_naive = np.random.normal(0.0, 1.0, size=N)
p_naive = np.mean(xs_naive > 3.0)
xs_is = np.random.normal(loc=mu_shift, scale=1.0, size=N)
qx = norm.pdf(xs_is, loc=mu_shift, scale=1.0)
px = norm.pdf(xs_is, loc=0.0, scale=1.0)
w = px / qx
indicators = (xs_is > 3.0).astype(float)
p_is = np.mean(w * indicators)
ess = (w.sum()**2) / (np.sum(w**2) + 1e-300)
return p_naive, p_is, ess, w, xs_is
N = 2000
reps = 300
mus = [3.0, 2.5]
results = {}
for mu in mus:
p_naive_list = []
p_is_list = []
ess_list = []
for r in range(reps):
p_naive, p_is, ess, w, xs_is = single_run_compare(N, mu_shift=mu)
p_naive_list.append(p_naive)
p_is_list.append(p_is)
ess_list.append(ess)
p_naive_arr = np.array(p_naive_list)
p_is_arr = np.array(p_is_list)
results[mu] = {
"p_naive_mean": p_naive_arr.mean(),
"p_naive_std": p_naive_arr.std(ddof=1),
"p_is_mean": p_is_arr.mean(),
"p_is_std": p_is_arr.std(ddof=1),
"ESS_mean": np.mean(ess_list),
"p_naive_arr": p_naive_arr,
"p_is_arr": p_is_arr
}
print("比较结果(使用 N=2000, reps=300):")
for mu in mus:
r = results[mu]
print(f"\nproposal N({mu},1):")
print(f" naive: mean={r['p_naive_mean']:.3e}, std={r['p_naive_std']:.3e} (naive Monte Carlo(直接从 N(0,1) 采样)估计的标准差)")
print(f" IS : mean={r['p_is_mean']:.3e}, std={r['p_is_std']:.3e} (IS 得到的标准差)")
print(f" mean ESS (IS) ~ {r['ESS_mean']:.1f} (out of N={N})")
if r['p_is_std']>0:
print(f" variance reduction factor (naive_var / IS_var) ≈ {(r['p_naive_std']**2)/(r['p_is_std']**2):.3f} (观察是否 IS 显著减少了方差,若有大幅度降低,则说明 IS 在估计稀有事件(尾概率)时非常有效。)")
else:
print(" IS variance is (near) zero")
# single-run running plots for visual comparison
xs_naive = np.random.normal(0.0, 1.0, size=N)
running_naive = np.cumsum((xs_naive > 3.0).astype(float)) / np.arange(1, N+1)
xs_is = np.random.normal(loc=3.0, scale=1.0, size=N)
qx = norm.pdf(xs_is, loc=3.0, scale=1.0); px = norm.pdf(xs_is, loc=0.0, scale=1.0)
w = px/qx; inds = (xs_is > 3.0).astype(float)
running_is = np.cumsum(w*inds) / np.arange(1, N+1)
plt.figure(figsize=(9,4))
plt.plot(running_naive, label='naive running estimate')
plt.plot(running_is, label='IS running estimate (mu=3)')
plt.axhline(p_true, linestyle='--', linewidth=1.5, label='true p')
plt.title('Running estimates: naive vs IS (single realization)')
plt.xlabel('n')
plt.ylabel('estimate of P(Z>3)')
plt.legend()
plt.show()
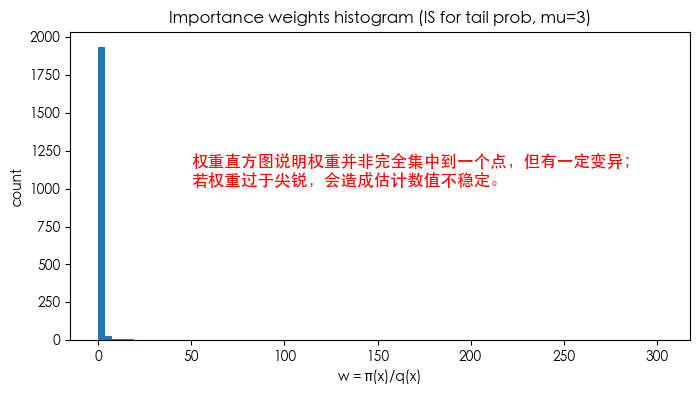
plt.figure(figsize=(8,4))
plt.hist(w, bins=80)
plt.text(50, 1020, '权重直方图说明权重并非完全集中到一个点,但有一定变异;\n若权重过于尖锐,会造成估计数值不稳定。', fontsize=12, color='red')
plt.title('Importance weights histogram (IS for tail prob, mu=3)')
plt.xlabel('w = π(x)/q(x)')
plt.ylabel('count')
plt.show()
=== 示例:估计尾概率 p = P(Z>3) ===
真实 p = 1.349898e-03
比较结果(使用 N=2000, reps=300):
proposal N(3.0,1):
naive: mean=1.372e-03, std=7.776e-04 (naive Monte Carlo(直接从 N(0,1) 采样)估计的标准差)
IS : mean=1.353e-03, std=5.413e-05 (IS 得到的标准差)
mean ESS (IS) ~ 18.6 (out of N=2000)
variance reduction factor (naive_var / IS_var) ≈ 206.352 (观察是否 IS 显著减少了方差,若有大幅度降低,则说明 IS 在估计稀有事件(尾概率)时非常有效。)
proposal N(2.5,1):
naive: mean=1.412e-03, std=8.001e-04 (naive Monte Carlo(直接从 N(0,1) 采样)估计的标准差)
IS : mean=1.352e-03, std=6.596e-05 (IS 得到的标准差)
mean ESS (IS) ~ 35.6 (out of N=2000)
variance reduction factor (naive_var / IS_var) ≈ 147.125 (观察是否 IS 显著减少了方差,若有大幅度降低,则说明 IS 在估计稀有事件(尾概率)时非常有效。)
如何根据目标与任务选择 $q$
- 若估计形如 $\mu=\mathbb{E}_\pi[h]$,考虑 q(x) ∝ |h(x)|π(x)(理论最优,实践上可用近似或分段混合实现)。
- 对于尾概率或稀有事件,使用倾斜/平移(exponential tilting / shift)把质心移入稀有事件区域(示例2 即把 N(0,1) 平移到 N(μ,1),μ≈3)。
- 混合提议:若单一 q 难以覆盖所有重要区域,使用混合分布 q = Σ α_j q_j(多重重要性采样)。
- 数值稳定:用 log 权重处理并进行常数移位(例如 subtract max(log w))再 exponentiate 以得到稳定的归一化权重。
- 诊断:查看权重的 CV(coef. of variation)、ESS、最大权重占比(是否有一个或极少数权重占据大部分质量)。如果 ESS 很小(比如 < 10% of N),需小心结果的稳健性。
- 若可行,做自适应:先用粗略 q 估计重要区域,然后调整 q(例如参数化 q 的均值/方差或混合权重)再做第二轮采样(adaptive IS / adaptive importance sampling)。
# 重要性采样估计积分:比较不同 proposal 的效果,体会“好 proposal 分布 = 更低方差”。
# 积分函数
f = lambda x: 1/(1+x**2)
# 提议分布 1:均匀(0,1)
N = 10000
x = np.random.rand(N) # g(x)=1
weights = f(x) / 1
I_est_uniform = np.mean(weights)
# 提议分布 2:Beta(0.5,0.5) → 偏向 0 和 1,贴合 f(x) 的形状
from scipy.stats import beta
x = beta.rvs(0.5,0.5,size=N)
g = beta.pdf(x,0.5,0.5)
weights = f(x)/g
I_est_beta = np.mean(weights)
print(f"真实值: {np.pi/4:.5f}")
print(f"均匀 proposal 估计: {I_est_uniform:.5f}")
print(f"Beta proposal 估计: {I_est_beta:.5f}")
真实值: 0.78540
均匀 proposal 估计: 0.78474
Beta proposal 估计: 0.78740
与拒绝采样/其它方法的关系
- 拒绝采样要求找到 $M$ 使 $\pi\le Mq$,接受率 $1/M$,在高维常困难。
- IS不需要 $M$,只需能算 $\pi/q$(或 $f/q$)。但如果 $q$ 与 $\pi$ 差别太大,权重会退化。
- SMC/粒子滤波等会在 IS 上加入重采样与序贯更新来缓解退化。
方差缩减技术
在蒙特卡罗中,核心问题是样本方差大,收敛慢。因此,我们希望在相同样本预算下,把估计方差尽可能压低,从而更快地得到更准的结果。
方法1️⃣ 对偶变量(Antithetic Variates)
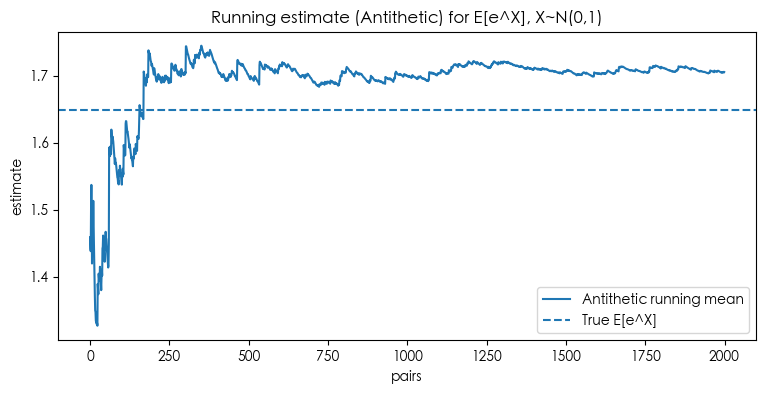
想法:构造带负相关的样本对,使样本平均的方差减小。 对对称分布(如 $N(0,1)$),常用成对样本 $(X,-X)$。若被积函数 $g$ 单调,通常 $g(X)$ 与 $g(-X)$ 负相关。
估计量(以两点为一对):
$$ \hat\mu_{\text{anti}}=\frac{1}{m}\sum_{i=1}^m \frac{g(X_i)+g(-X_i)}{2}. $$方差:
$$ \operatorname{Var}(\hat\mu_{\text{anti}})=\frac{1}{m}\frac{\operatorname{Var}(g(X))+ \operatorname{Var}(g(-X))+2\operatorname{Cov}(g(X),g(-X))}{4}. $$若协方差为负,方差自然下降。示例中 $g(x)=e^x$、$X\sim N(0,1)$,确有显著负协方差。
方法2️⃣ 控制变量(Control Variates)
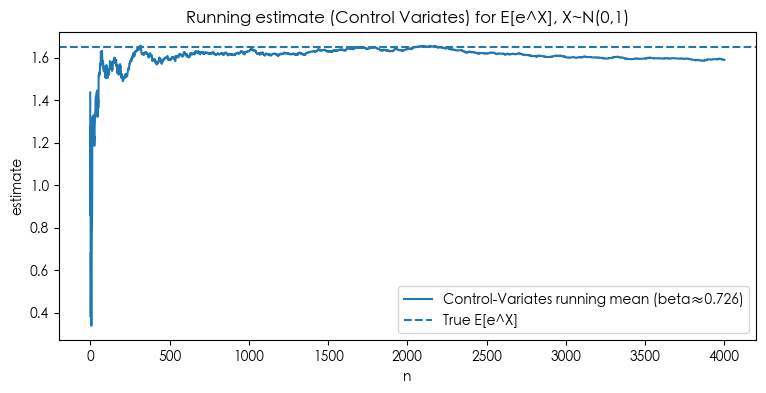
想法:找一个与目标函数高度相关、且期望已知的变量 $Y$,用它纠偏:
$$ \hat\mu_{\text{cv}}=\bar{h}-\beta(\bar{Y}-\mathbb{E}[Y]), \quad \beta^*=\frac{\operatorname{Cov}(h,Y)}{\operatorname{Var}(Y)}. $$直觉:$\bar{Y}$若高于其真均值,往往意味着$\bar{h}$也偏高,用$\beta(\bar{Y}-\mathbb{E}[Y])$把它拉回去。 实际使用时 $\beta^*$未知,用样本协方差/方差估计即可(几乎无偏且一致)。
示例:估计 $\mu_1=E[e^X]$,$X\sim N(0,1)$
真值 $e^{1/2}\approx 1.6487$。
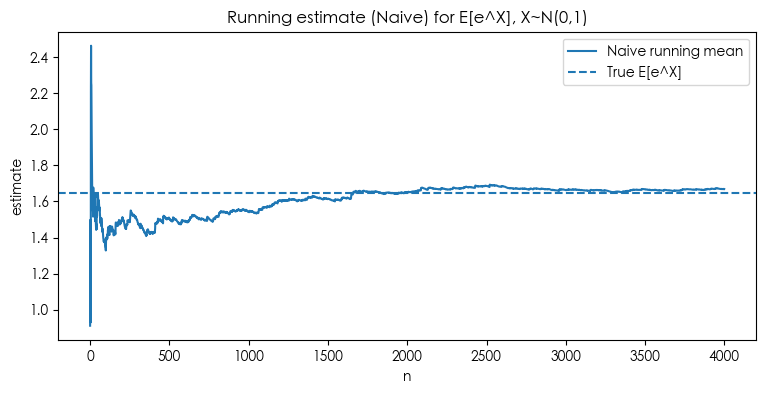
- Naive:sd ≈ 0.0475
- 对偶变量法(Antithetic):sd ≈ 0.0362,VRF ≈ 1.72(方差降到 ~58%)
- 控制变量法(Control Variates)(用 $Y=X^2-1$):sd ≈ 0.0395,VRF ≈ 1.45
- 这里,$h(X)=e^X$、控制变量 $Y=X^2-1$(其均值 0 已知),二者强相关,能显著降方差。
- 估出来的最佳 $\beta$ 在多次重复中平均约 0.839。
下图中,能看到三条“运行中估计”曲线都围着真值虚线收敛; 对偶变量和控制变量的曲线抖动明显更小。
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from math import exp
np.random.seed(2025)
mu1_true = np.exp(0.5)
def mc_naive_expX(N):
X = np.random.normal(0.0, 1.0, size=N)
g = np.exp(X)
return g.mean(), X, g
def mc_antithetic_expX(N):
M = (N // 2)
Z = np.random.normal(0.0, 1.0, size=M)
Y = (np.exp(Z) + np.exp(-Z)) / 2.0
return Y.mean(), Z, Y
def mc_controlvar_expX(N):
X = np.random.normal(0.0, 1.0, size=N)
h = np.exp(X)
Y = X**2 - 1.0
Y_mean = Y.mean()
#print(f"Control variates: Y (=X^2-1) mean = {Y_mean:.6f}")
h_mean = h.mean()
cov_hY = np.mean((h - h_mean)*(Y - Y_mean))
var_Y = np.var(Y, ddof=0)
beta_hat = cov_hY / (var_Y + 1e-12)
est = np.mean(h - beta_hat * Y) # here, E[Y] = 0, so we can use h directly
return est, X, h, Y, beta_hat
N_run = 4000
val_naive, Xn, gn = mc_naive_expX(N_run)
running_naive = np.cumsum(gn) / np.arange(1, N_run+1)
val_anti, Za, Ya = mc_antithetic_expX(N_run)
running_anti = np.cumsum(Ya) / np.arange(1, Ya.size+1)
val_cv, Xc, hc, Yc, beta_hat = mc_controlvar_expX(N_run)
cv_terms = hc - beta_hat * Yc
running_cv = np.cumsum(cv_terms) / np.arange(1, N_run+1)
plt.figure(figsize=(9,4))
plt.plot(running_naive, label='Naive running mean')
plt.axhline(mu1_true, linestyle='--', linewidth=1.5, label='True E[e^X]')
plt.title('Running estimate (Naive) for E[e^X], X~N(0,1)')
plt.xlabel('n')
plt.ylabel('estimate')
plt.legend()
plt.show()
plt.figure(figsize=(9,4))
plt.plot(running_anti, label='Antithetic running mean')
plt.axhline(mu1_true, linestyle='--', linewidth=1.5, label='True E[e^X]')
plt.title('Running estimate (Antithetic) for E[e^X], X~N(0,1)')
plt.xlabel('pairs')
plt.ylabel('estimate')
plt.legend()
plt.show()
plt.figure(figsize=(9,4))
plt.plot(running_cv, label=f'Control-Variates running mean (beta≈{beta_hat:.3f})')
plt.axhline(mu1_true, linestyle='--', linewidth=1.5, label='True E[e^X]')
plt.title('Running estimate (Control Variates) for E[e^X], X~N(0,1)')
plt.xlabel('n')
plt.ylabel('estimate')
plt.legend()
plt.show()
def replicate_stats(mu_true, N, reps=300):
naive_vals = []
anti_vals = []
cv_vals = []
betas = []
for _ in range(reps):
v1, *_ = mc_naive_expX(N)
v2, *_ = mc_antithetic_expX(N)
v3, *rest = mc_controlvar_expX(N)
beta_hat_r = rest[-1]
naive_vals.append(v1)
anti_vals.append(v2)
cv_vals.append(v3)
betas.append(beta_hat_r)
naive_vals = np.array(naive_vals)
anti_vals = np.array(anti_vals)
cv_vals = np.array(cv_vals)
betas = np.array(betas)
sd_naive = np.std(naive_vals, ddof=1)
sd_anti = np.std(anti_vals, ddof=1)
sd_cv = np.std(cv_vals, ddof=1)
vrf_anti = (sd_naive**2) / (sd_anti**2 + 1e-12)
vrf_cv = (sd_naive**2) / (sd_cv**2 + 1e-12)
bias_naive = naive_vals.mean() - mu_true
bias_anti = anti_vals.mean() - mu_true
bias_cv = cv_vals.mean() - mu_true
return {
"naive_mean": naive_vals.mean(), "naive_sd": sd_naive, "naive_bias": bias_naive,
"anti_mean": anti_vals.mean(), "anti_sd": sd_anti, "anti_bias": bias_anti, "VRF_anti": vrf_anti,
"cv_mean": cv_vals.mean(), "cv_sd": sd_cv, "cv_bias": bias_cv, "VRF_cv": vrf_cv,
"beta_hat_mean": betas.mean(), "beta_hat_sd": betas.std(ddof=1)
}
stats_A = replicate_stats(mu1_true, N=2000, reps=300)
dfA = pd.DataFrame({
"method": ["Naive", "Antithetic", "Control Variates"],
"mean_estimate": [stats_A["naive_mean"], stats_A["anti_mean"], stats_A["cv_mean"]],
"std_over_reps": [stats_A["naive_sd"], stats_A["anti_sd"], stats_A["cv_sd"]],
"bias": [stats_A["naive_bias"], stats_A["anti_bias"], stats_A["cv_bias"]],
"VRF_vs_Naive": [1.0, stats_A["VRF_anti"], stats_A["VRF_cv"]]
})
display(dfA)
print("=== 示例: E[e^X], X~N(0,1) ===")
print(f"True value = {mu1_true:.6f}")
print(f"Naive : mean={stats_A['naive_mean']:.6f}, sd={stats_A['naive_sd']:.6f}")
print(f"Anti : mean={stats_A['anti_mean']:.6f}, sd={stats_A['anti_sd']:.6f}, VRF≈{stats_A['VRF_anti']:.2f}")
print(f"Control : mean={stats_A['cv_mean']:.6f}, sd={stats_A['cv_sd']:.6f}, VRF≈{stats_A['VRF_cv']:.2f}")
print(f"(beta_hat across reps: mean≈{stats_A['beta_hat_mean']:.3f}, sd≈{stats_A['beta_hat_sd']:.3f})")
print("")
| method | mean_estimate | std_over_reps | bias | VRF_vs_Naive | |
|---|---|---|---|---|---|
| 0 | Naive | 1.649034 | 0.047489 | 0.000313 | 1.000000 |
| 1 | Antithetic | 1.648440 | 0.036174 | -0.000281 | 1.723407 |
| 2 | Control Variates | 1.651178 | 0.039462 | 0.002457 | 1.448168 |
=== 示例: E[e^X], X~N(0,1) ===
True value = 1.648721
Naive : mean=1.649034, sd=0.047489
Anti : mean=1.648440, sd=0.036174, VRF≈1.72
Control : mean=1.651178, sd=0.039462, VRF≈1.45
(beta_hat across reps: mean≈0.839, sd≈0.137)
方法3️⃣ 分层抽样(Stratified Sampling, 1D≈LHS)
我们要算一个积分,比如:
$$ I = \int_0^1 f(x) \, dx $$最朴素的 蒙特卡洛估计 是:
在 $[0,1]$ 区间均匀随机抽样 $N$ 个点 $U_i \sim \text{Uniform}(0,1)$,
然后取平均:
$$ \hat{I}_{\text{MC}} = \frac{1}{N} \sum_{i=1}^N f(U_i). $$
问题:点可能“挤在一起”或“漏掉某个区域”,导致估计波动大(方差大)。
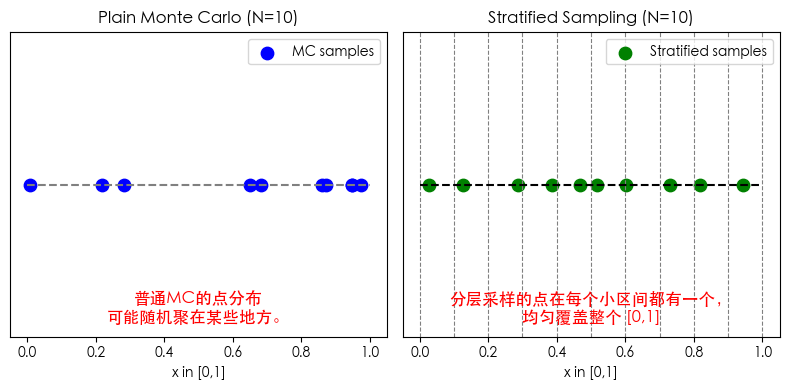
✨ 分层抽样的想法
把区间 分成若干层(小区间),保证每个小区间都被覆盖。
例子:$N=10$,把 $[0,1]$ 均分成 10 段:
$$ [0,0.1), [0.1,0.2), \ldots, [0.9,1.0) $$做法:
- 在每个小区间里,各抽 一个随机点;
- 计算函数值;
- 最后取平均。
这样:
- 每个小区间都被采样,不会“漏掉”某部分;
- 抽样更均匀,方差大大降低。
数学上:
$$ \hat{I}_{\text{strat}} = \frac{1}{N} \sum_{j=1}^N f\Big(U_j^*\Big), \quad U_j^* \sim \text{Uniform}\Big(\tfrac{j-1}{N}, \tfrac{j}{N}\Big). $$👉 直观理解:
- 普通 MC 有可能随机点集中在区间一部分 → 估计不稳定;
- 分层抽样强制每个子区间都取样 → 保证全覆盖 → 方差极小。
# 普通 MC 和分层采样在区间 [0,1] 的采样点分布
import numpy as np
import matplotlib.pyplot as plt
N = 10 # 分层数量
# 普通蒙特卡洛采样
mc_samples = np.random.rand(N)
# 分层采样
strata = np.linspace(0, 1, N+1)
u = np.random.rand(N)
strat_samples = strata[:-1] + u * (strata[1:] - strata[:-1])
# 绘图
plt.figure(figsize=(8, 4))
# 普通 MC
plt.subplot(1, 2, 1)
plt.scatter(mc_samples, np.zeros(N), color="blue", s=80, label="MC samples")
plt.hlines(0, 0, 1, colors="gray", linestyles="dashed")
plt.text(0.5, -0.05, '普通MC的点分布\n可能随机聚在某些地方。', fontsize=12, color='red', ha='center')
plt.title("Plain Monte Carlo (N=10)")
plt.xlabel("x in [0,1]")
plt.yticks([])
plt.legend()
# 分层采样
plt.subplot(1, 2, 2)
plt.scatter(strat_samples, np.zeros(N), color="green", s=80, label="Stratified samples")
for i in range(N+1):
plt.axvline(strata[i], color="gray", linestyle="dashed", linewidth=0.8) # 画出分层边界
plt.hlines(0, 0, 1, colors="black", linestyles="dashed")
plt.text(0.5, -0.05, '分层采样的点在每个小区间都有一个,\n均匀覆盖整个 [0,1]', fontsize=12, color='red', ha='center')
plt.title("Stratified Sampling (N=10)")
plt.xlabel("x in [0,1]")
plt.yticks([])
plt.legend()
plt.tight_layout()
plt.show()
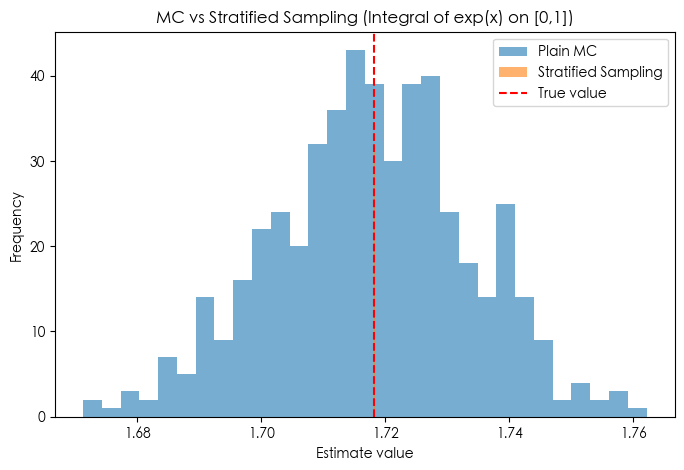
示例:估计 $\mu_2=\int_0^1 e^u\,du=e-1$
我们来对比一下 普通蒙特卡洛 和 分层抽样,用目标积分:
$$ I = \int_0^1 e^x \, dx = e - 1 \approx 1.718. $$结果显示得很清楚:
- 普通蒙特卡洛 (MC):均值 ≈ 1.7171,标准差 ≈ 0.016
- 分层抽样 (Stratified):均值 ≈ 1.7183,标准差 ≈ 0.000016(几乎没波动!)
图里蓝色直方图(MC)很宽,橙色直方图(分层)非常窄(几乎看不到),几乎精确落在真值 $e-1$ 上。
这正是分层在“平滑一维积分”里非常猛的经典现象:等距分层+每层均匀取点,极大降低了“运气”带来的波动。
import numpy as np
import matplotlib.pyplot as plt
# 积分目标函数
f = lambda x: np.exp(x)
true_val = np.e - 1
def mc_integral(N=1000):
x = np.random.rand(N)
return f(x).mean()
def stratified_integral(N=1000):
# 将区间[0,1]均匀分成N个子区间。例如,当N=4时,strata=[0.0,0.25,0.5,0.75,1.0], 即分成 [0,0.25),[0.25,0.5),[0.5,0.75),[0.75,1.0)
strata = np.linspace(0, 1, N+1)
# 每个区间采样一个点,即生成 N 个在 [0,1] 区间的随机数。
u = np.random.rand(N)
# 把这些随机数“缩放到”各自的小区间
# strata[:-1] 是所有小区间的 左端点,例如,[0,0.25,0.5,0.75]。
# strata[1:] 是所有小区间的 右端点,例如,[0.25,0.5,0.75,1.0]。
# u * (strata[1:] - strata[:-1]) 是每个小区间的长度乘以随机数 u,得到在每个小区间内的随机点。
# 最终得到的 x 是在 [0,1] 区间内均匀分布的 N 个点。
x = strata[:-1] + u * (strata[1:] - strata[:-1])
return f(x).mean() # 计算积分估计
# 多次实验比较方差
R = 500
N = 1000
mc_vals = np.array([mc_integral(N) for _ in range(R)])
strat_vals = np.array([stratified_integral(N) for _ in range(R)])
print(f"True value = {true_val:.6f}")
print(f"MC: mean={mc_vals.mean():.6f}, std={mc_vals.std():.6f}")
print(f"Stratified: mean={strat_vals.mean():.6f}, std={strat_vals.std():.6f}")
# 可视化分布
plt.figure(figsize=(8,5))
plt.hist(mc_vals, bins=30, alpha=0.6, label="Plain MC")
plt.hist(strat_vals, bins=30, alpha=0.6, label="Stratified Sampling")
plt.axvline(true_val, color="red", linestyle="--", label="True value")
plt.title("MC vs Stratified Sampling (Integral of exp(x) on [0,1])")
plt.xlabel("Estimate value")
plt.ylabel("Frequency")
plt.legend()
plt.show()
True value = 1.718282
MC: mean=1.717769, std=0.015955
Stratified: mean=1.718282, std=0.000016
实战指南
- 优先匹配场景
- 单调/对称分布:先试对偶变量。
- 有天然“近似线性/已知均值”的特征可利用:上控制变量。
- 积分域结构清晰、函数平滑:试分层/LHS;高维也能用 LHS 逐维分层。
- 如何挑控制变量
- 与目标 $h(X)$ 强相关(|ρ| 越大越好)。
- 均值 $\mathbb{E}[Y]$ 已知或容易精确求。
- 例:期权定价里,选取易定价的近似产品作为控制变量。
- 分层怎么分
- 1D:等距分层通常就很强。
- 多维:用 LHS(每一维都分层并做随机置换),既省事又有效。
- 若知道某些维/区域更重要,可做非等距分层、对关键层多分配样本(比例与层内方差/重要度匹配)。
- 和重要性采样的关系
- IS 也是方差缩减方法之一,但常用于稀有事件/尾部;而对偶/控制/分层在“正常、平滑”的任务上更通用、稳健。
- 实战可组合:如“分层 + IS”、“控制变量 + IS”。
- 诊断与稳健性
- 多做重复试验估计标准差/VRF(我在代码里就这么做)。
- 观察“运行中估计”曲线是否更稳、更快贴近真值。
- 控制变量里,$\beta$ 可在小试后固定,避免“一边估 $\beta$ 一边用”带来的轻微有限样本偏差(虽说通常很小)。
Scan to Share
微信扫一扫分享