发表于 January 1, 0001 | 0 个字 • 其它语言: EN
自监督学习(SSL)是一种利用数据的内在特征(包括光谱、空间和时间特征)从未标注数据中预训练模型的方法,它通过设计借口任务(Pretext Tasks)(即对数据应用转换并让网络预测数据是如何被转换),从而使模型能够学习有意义的表示(representation)。
为什么要使用自监督学习(SSL)?
- 深度学习通常需要大量的标注数据,但是标注数据存在稀缺、获取成本高昂、标注过程繁琐等问题。
- 相比之下,未标注数据非常丰富,例如卫星档案拥有 PB 级别的数据。
- 可迁移性(Transferability):预训练模型可以迁移到下游任务中。
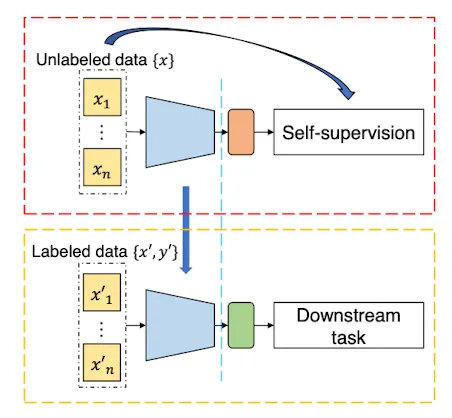
SSL 模型
SSL 有三种主要范式:
1. 联合嵌入 SSL (Joint Embedding SSL)
核心思想:使用共享参数的 Siamese 架构。通过数据增强生成相似图像(视图),强制对增强操作保持不变性(invariance)。
问题:可能会发生模型
联合嵌入的自监督学习方法:
- 对比学习方法 (Contrastive Methods)
- 核心思想:将正样本对(同一图像的不同视图/增强)在嵌入空间中拉近,将负样本(不同图像)推开。
- 关键特性:需要负样本或大批次大小。
- 示例
- SimCLR
- MoCo。
- 聚类方法 (Clustering Methods)
- 核心思想:通过将相似样本分组为聚类来学习嵌入,无需明确的负样本。
- 关键特性:联合学习表示和聚类分配。
- 示例:
- SwAV
- Deep Cluster(非联合嵌入)
- 蒸馏方法 (Distillation Methods)
- 核心思想:一个“学生”编码器匹配“教师”编码器在增强数据上的输出分布,教师通常通过 EMA (指数移动平均) 更新。
- 关键特性:无需负样本,依赖于非对称架构(教师 vs. 学生)来避免坍塌。
- 示例:
- BYOL
- DINO、DINOv2 和 DINOv3
- 正则化方法 (Regularization Methods)
- 核心思想:鼓励嵌入在不同维度之间去相关(maximize information per feature)。
- 关键特性:通过惩罚嵌入维度之间的相关性来避免坍塌,无需负样本。
- 示例:
- Barlow Twins
- VICReg
2. 掩码图像建模 (Masked Image Modeling, MIM)
核心思想:将图像拆分为图像块,掩盖一个子集 $\mathcal{M}$,并从可见上下文 $x_{\sim \mathcal{M}}$ 中学习。
- 一般想法:从可见的图像块中预测缺失的图像块。
- 通常使用高掩码比例(约 75%)。
预测目标:
- 像素重构:MAE (Masked Autoencoders)、SimMIM。
- 特征回归:MaskFeat。
- Token 预测:BEiT。
特点对比:
- 优点:概念简单,高效,适合低级下游任务(如去噪、超分辨率)。
- 缺点:对于高级任务(如分类)较弱。
3. 混合(掩码 + 联合嵌入)(Hybrid (Masking + Joint Embedding))
示例:
- I-JEPA (Image-based Joint Embedding Predictive Architecture)。
- 核心思想:预测(重构)抽象表示而不是像素。